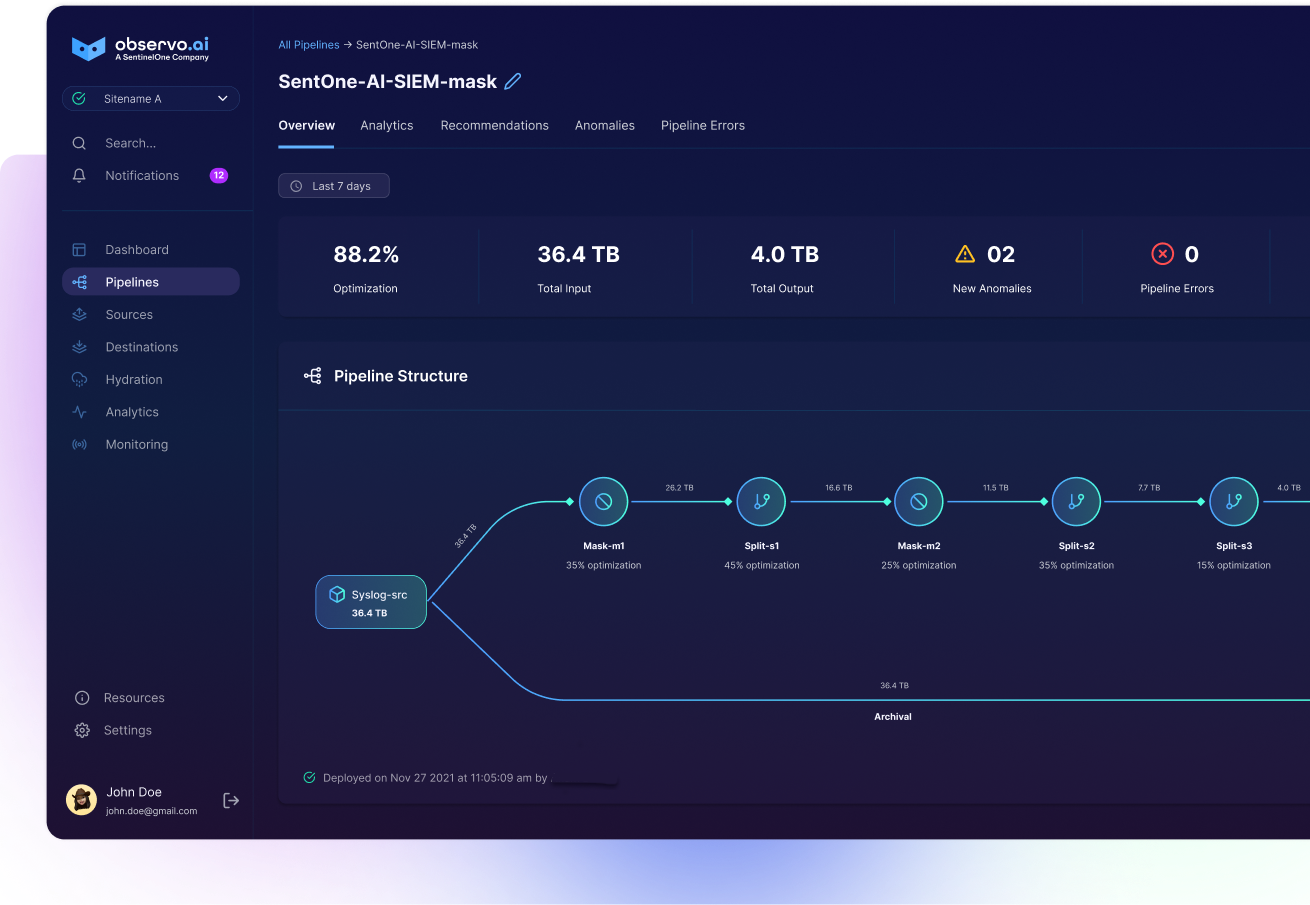
Observo Data Lake
Feature Overview
Observo Data Lake ensures compliance with data retention while cutting costs, storing Security and Observability data in compressed, open formats for as little as 1% of analytics index costs. With natural language queries, flexible retention, and on-demand rehydration, access insights and analyze data anytime.
Secure, Long-Term Data Retention
Observo Data Lake allows you to retain data securely and affordably for extended periods. It makes it easy to comply with data retention regulations and supports on-demand historical analysis and investigations.


Natural Language Queries (Beta)
Observo Data Lake makes it easy to access the data for analysis using technical or natural language queries. Anyone can easily search the archive without having to be a data scientist or mastering complex query languages.
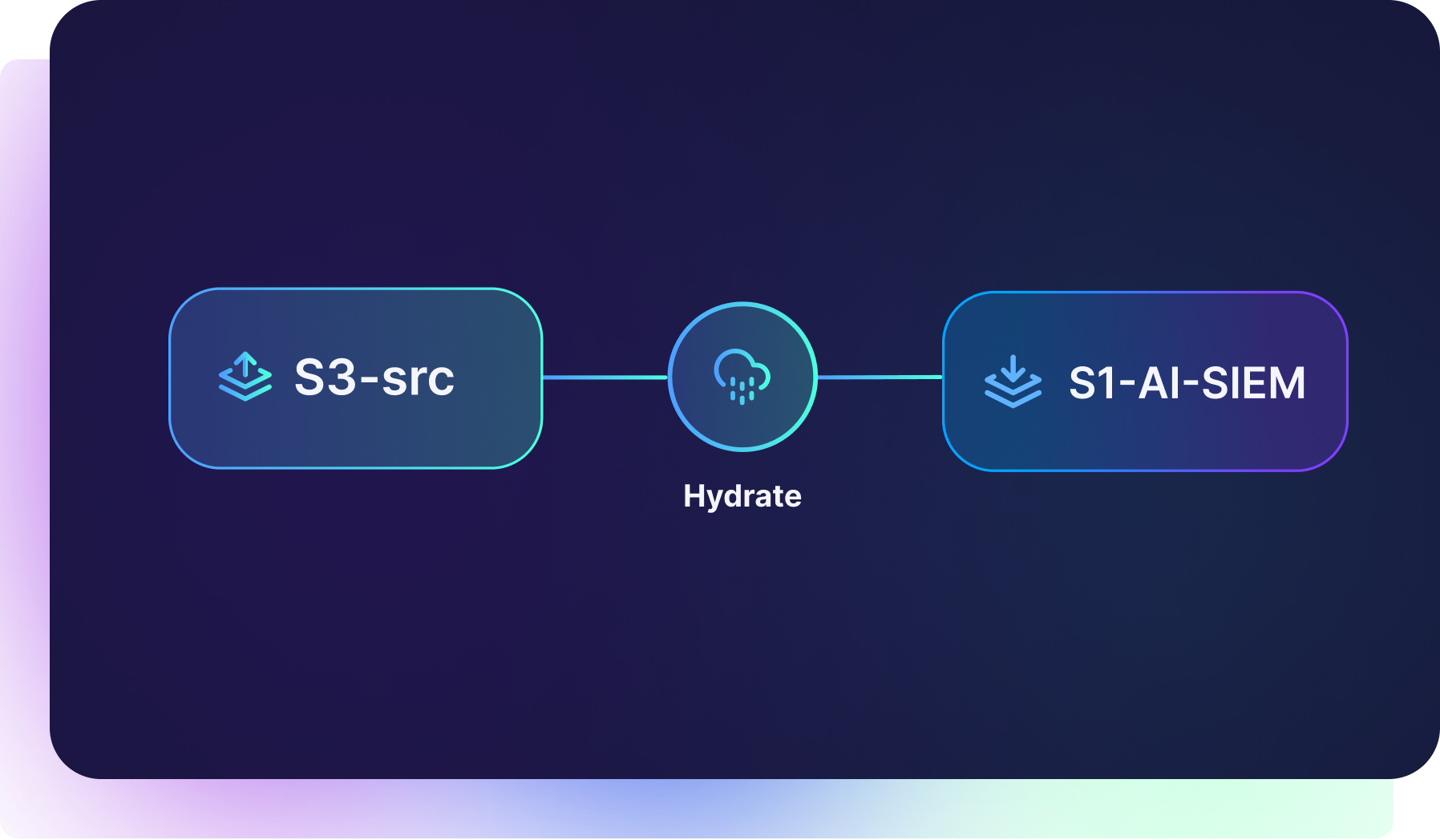
On-Demand Data Hydration
Observo Data Lake allows you to hydrate archived data on-demand and seamlessly route it to your choice of tools, including SIEMs, observability platforms, data warehouses, and more—all with a single click.

Enable Tiered Retention Policies
Observo Data Lake enables you to define tiered retention policies tailored to your use cases, optimizing costs by storing data in low-cost, infrequent access tiers like Glacier for extended periods or enabling easier access for shorter term retention for different data classes.
Open Format Data Storage
Observo Data Lake stores your data in open formats like Parquet, OCSF, or JSON, providing flexibility and eliminating vendor lock-in. Normalized data is easier to organize, faster to search, and simple to translate into other formats for future analysis or investigation.


Unified View of Data
Observo Data Lake provides a centralized view of your data across multiple silos without the need for physical migration. Access all your data in one place while minimizing data egress costs and ensuring seamless analysis.