Solving the Getting Data In Problem: Ingesting and Normalizing Heterogeneous Data at Scale

The Problem
In today’s data-driven world, businesses rely on logs to monitor health, troubleshoot issues, and gain insights for better decision-making. Such monitoring is often achieved through observability tools, like Observo AI. However, integrating observability pipelines in the modern infrastructure is complex, and engineering teams often face several challenges when onboarding data into their observability pipelines:
- Lack of standardization: Logs are generated by application services, cloud infrastructure, or security services—each following its schema and encoding. Some of them may have raw text or syslog formats, while others may follow structured formats like JSON or CSV. Without a universal standard, teams must manually configure the ingestion pipelines for each source.
- Schema Inconsistencies: Even within the same system, log formats can change over time, requiring constant updates to parsing rules.
- Parsing, transformation, and enrichment: Raw logs often need processing before they can be useful. Teams must extract relevant fields, map them to a target schema, and enrich them with metadata such as timestamps or geo-locations.
These challenges create bottlenecks that consume precious engineering bandwidth and reduce the effectiveness of observability solutions. Additionally, it also delays the ability to derive insights and slows down incident response time, leading to huge engineering cost overheads. This is where Observo AI simplifies the process — automating log ingestion, normalization, and enrichment to transform your raw data into actionable insights.
How Do We Solve It?
.png)
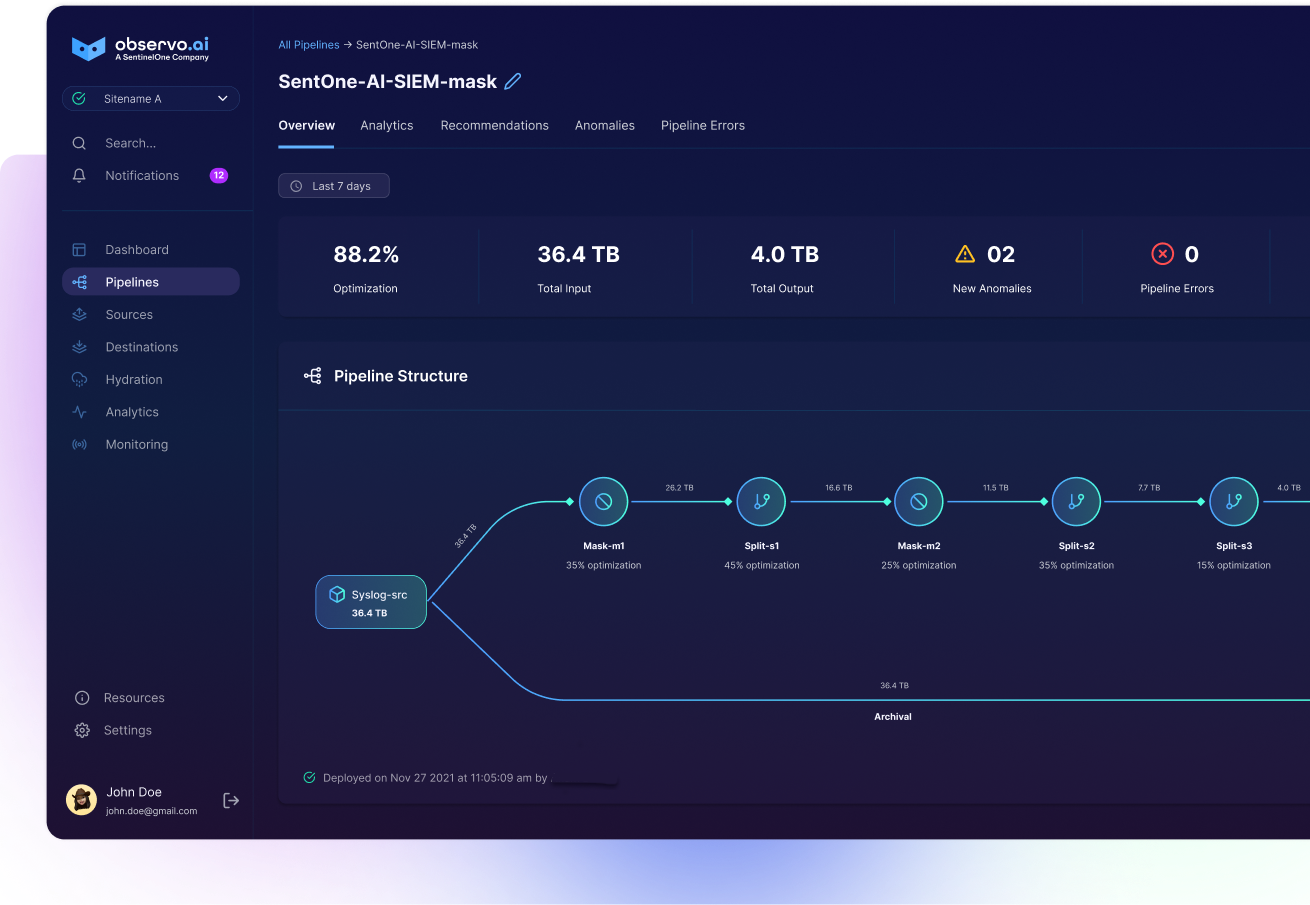
At Observo, we’re committed to a smooth onboarding experience for our customers. We provide that through a platform of capabilities that assist data engineers in automating the mundane work. Here’s how we make it happen:
Out-of-the-Box (OOB) Parsers for Standard Log Types
Observo AI comes with a library of pre-built parsers designed for standard log types, such as security logs (e.g., PANW), Cloud & Network Logs (e.g., VPC Flow Logs, AWS CloudTrail), and Windows Event Logs. These parsers are specifically optimized for common log formats, ensuring that onboarding these sources is effortless and quick.
Pre-Built Transforms for Data Optimization
ObservoAI also includes pre-built transforms that allow teams to summarize, optimize, and serialize data before it is written to downstream systems, like Splunk, ElasticSearch, or any other data sink. This feature ensures that only the relevant and compact data is sent to the destinations. Being serialized into correct third-party formats, this data is ready to be efficiently indexed and queried.
Flexible Parsing with Auto Generated Grok Transforms
For non-standard logs or custom sources, we provide support for writing powerful Grok transforms and Lua Scripts.
- Grok Transforms provides a robust pattern-matching engine to extract key log components (e.g., IP addresses, timestamps, and HTTP status codes) from unstructured logs.
- Lua scripts allow for custom parsing logic and transformations for logs that don’t follow pre-defined patterns.
To further enhance the onboarding experience, our AI-powered copilot, Orion, auto-detects grok patterns from unstructured log formats, reducing the need for manual intervention. By combining AI with Grok, we unlock effortless onboarding of any log sources to our platform.
Data Insights to Guide Pipeline Configuration
One of the standout features of Observo AI is the data insights dashboard, which provides engineers with real-time visibility into log patterns as they are ingested. Such visibility allows them to identify patterns to filter out, enrich logs with contextual information, or plan and optimize pipeline configuration.
This rich out-of-band analytics provides security and DevOps teams with deep insights into the evolving nature of their telemetry data.
Looking Ahead
With Observo AI, engineering teams no longer have to struggle with complex log pipelines, changing schemas, or manual parsing. By automating ingestion, normalization, and enrichment, Observo AI ensures that logs are instantly usable—truly unlocking observability at scale. Observo AI eliminates these operational inefficiencies, empowering teams to shift their focus from managing data complexity to driving real security and engineering outcomes.
"Before implementing Observo AI, our team spent countless hours manually configuring ingestion pipelines for each new data source. The lack of standardization across our diverse log formats was creating significant bottlenecks and slowing our incident response time. With Observo's automated log ingestion and AI-powered pattern detection, we've reduced our onboarding time by 85% and can now focus on solving real problems instead of wrestling with data formats. Their pre-built parsers and transforms have turned what was once our biggest technical headache into a seamless process that just works." - Director of Security Operations, Bill
As the complexity of modern systems continues to grow, the need for scalable observability becomes ever more critical. Observo AI’s automated approach to log management frees engineering teams from the headaches of manually managing log pipelines, enabling them to focus on what truly matters — optimizing performance and resolving issues faster. By providing instant access to enriched, normalized data, Observo AI empowers teams to gain real-time insights without being bogged down by the intricacies of data parsing.
Looking ahead, the ability to effortlessly scale observability will be an essential factor for any organization aiming to maintain operational excellence. With Observo AI, businesses are not just keeping up with the demands of modern infrastructure, but actively staying ahead of the curve. As data grows, so too does Observo AI’s ability to provide clarity, enabling teams to make more informed decisions and drive smarter, faster outcomes across their entire tech stack.