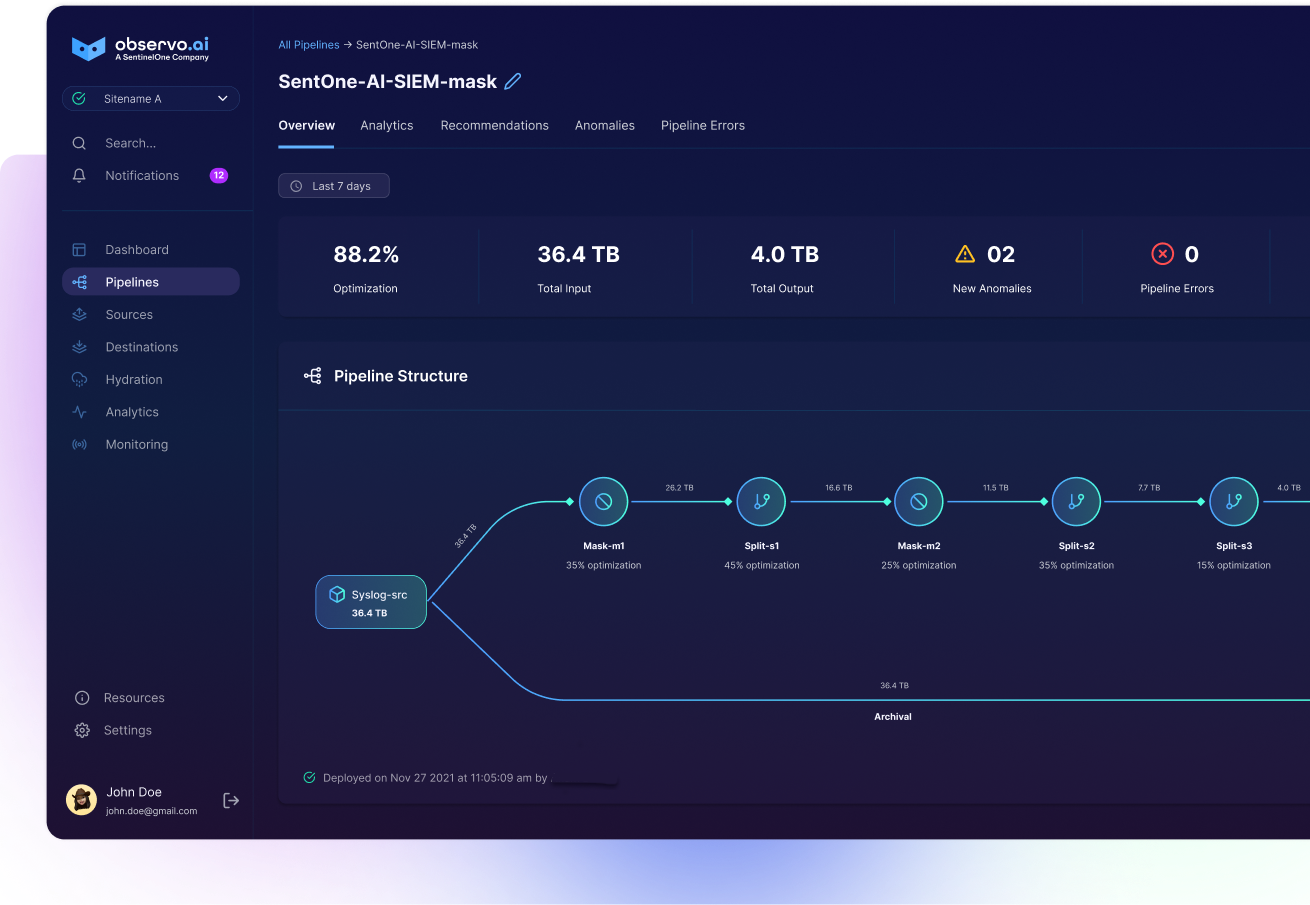
Better Together: Splunk ES & Observo AI Data Pipelines

Security data collection is the foundation of Splunk Enterprise Security (ES), but there are several challenges that organizations face when gathering and preparing data for effective analysis. These issues can impact the accuracy, efficiency, and value of the security insights derived from Splunk ES. These challenges can result in blind spots, inefficiencies, and inaccurate detection.
SOC Team Log Data Collection Challenges
Here are some of the challenges that weaken the ability of SOC teams to deliver a strong security posture with Splunk ES:
- Incomplete or Insufficient Data Coverage: Not all critical data sources are integrated into Splunk ES, leaving gaps in visibility. Missing logs from important systems can prevent the correlation of security events and lead to blind spots in threat detection.
- Data Volume Overload: Security teams often ingest excessive amounts of raw logs into Splunk, including redundant or low-value data such as debug logs, and unfiltered network traffic. This leads to Increased Splunk licensing costs (based on data ingestion volume) and lower performance due to bloated indexes and longer search query times.
- Lack of Data Normalization: Data from different sources such as firewalls, endpoints, and cloud services arrive in various formats, making it difficult for Splunk ES to apply consistent correlation or analysis. This leads to difficulty mapping data to the Splunk Common Information Model (CIM) and reduced effectiveness of detection rules, correlation searches, and dashboards.
- Poor Data Quality: Collected data may be incomplete, inaccurate, or lack critical fields such as missing timestamps, source IPs, or user identifiers. This leads to heightened false positives and negatives in alerts/dashboards and ineffective investigations due to incomplete event context.
- Inefficient Collection from Cloud Environments: Collecting logs from multi-cloud or hybrid environments is complex due to varied logging mechanisms, APIs, and storage formats. Splunk has an array of solutions to handle cloud-native integration but they’re often varied, confusing, and complex to implement.
- Log Content Duplication/Redundancy: The same event may be logged across multiple devices, leading to redundancy. This leads to increased storage, ingestion costs, and noise in search results and correlation rules.
- Lack of Contextual Enrichment: Raw logs often lack context, such as geolocation or asset criticality. This leads to SOC analysts spending more time correlating data manually and reducing the accuracy of automated alerts and dashboards.
- Compliance and Privacy Concerns: Regulations like GDPR or CCPA may restrict the collection of sensitive data such as PII, and user activity logs. This leads to organizations risking non-compliance if data collection and retention practices are not carefully managed.
- Unstructured or Complex Log Formats: Many logs arrive in unstructured or proprietary formats that are difficult to parse automatically. This leads to parsing errors or missed fields resulting in incomplete or unusable data in Splunk ES.
- High Cost of Collecting and Storing All Logs: Organizations often try to collect and store all possible data, driving up Splunk licensing and infrastructure costs. This leads to unsustainable costs without proportionate value from ingested data.
- Real-time Anomaly Detection: Lack of ability to analyze logs for anomalies before they reach Splunk ES. This leads to the inability to prioritize logs from high-risk areas such as production servers, critical databases, or identity providers while deprioritizing low-risk systems such as test or development environments.
Data Pipelines Ensure Better Data Continuity
These challenges increase costs, degrade performance, and hinder real-time threat detection. Addressing them requires implementing data pipelines. Observo AI data pipelines help you automate the optimization and reduction of security events right out of the box by over 80% or more.

Observo AI data pipelines reduce log ingestion while simultaneously increasing log coverage by intelligently processing, filtering, and enriching the data before it reaches downstream SIEMs such as Splunk ES. This approach optimizes the data flow, ensures that only relevant and high-value data is ingested, and expands the visibility into critical areas. Here’s how:
- Filtering Irrelevant or Noisy Data: Our data pipelines can remove repetitive, redundant, or low-value logs such as firewall drops or heartbeat events. This reduces the overall ingestion volume by cutting out "noise" while retaining logs relevant to security, compliance, and operational needs.
- Event Deduplication: Our data pipelines can detect and remove duplicate log entries that arise from multiple sources such as logs captured by multiple systems or devices reporting the same events. Additionally, our data pipelines can aggregate similar events such as repeated login failures into a single, enriched event with a count of occurrences. This reduces ingestion volume while still providing insights into trends and patterns.
- Log Sampling for Low-Value Data: For logs that are not critical but may still be useful for trend analysis or forensic investigation such as network flow logs, our data pipelines can send a representative sample rather than the entire dataset. You still retain coverage of all log types while minimizing the ingestion of less critical data.
- Prioritization of High-Value Data: Our data pipelines can prioritize logs from high-risk areas such as production servers, critical databases, or identity providers while deprioritizing low-risk systems such as test or development environments. Only logs flagged as severe such as critical errors or suspicious activity are sent downstream, while benign or low-priority events can be excluded. This ensures that critical security and operational logs are ingested while reducing unnecessary overhead.
- Enrichment Upstream: Our data pipelines add valuable metadata contexts such as geolocation, threat intelligence, user roles, or asset criticality to logs before ingestion. We can normalize logs to frameworks like the Common Information Model (CIM), making them more useful and actionable. This reduces the need to store and process raw, unstructured logs and increases the value of ingested logs, as they contain enriched actionable insights.
- Summarization of Non-Critical Logs: Our data pipelines offer pre-aggregated insights by aggregating logs into summaries or statistics. For example, instead of ingesting every individual packet from a network flow, our data pipelines can summarize traffic by source, destination, protocol, and volume. Failed logins can be summarized by username, source IP, and count. Our data pipelines can supply trend analysis that summarizes logs and provides visibility into patterns without the need for ingesting every individual event. This reduces ingestion volume but still provides coverage for security monitoring.
- Dynamic Routing, Enact Data Tiering: Logs can be routed to different destinations based on relevance. High-priority logs are sent to Splunk ES or other premium log management systems while low-priority logs are sent to cheaper storage solutions such as AWS S3. You can implement a tiered storage strategy for "hot" storage for real-time analytics versus "cold" storage for archival or compliance purposes. This reduces the cost of log ingestion while ensuring comprehensive coverage of all log types.
- Data Masking: Protects sensitive information within logs by obfuscating it, ensuring privacy and security during processing. It enables organizations to comply with regulations like GDPR or HIPAA while still allowing teams to use realistic, anonymized data for testing or security analysis. This reduces the risk of data breaches and helps maintain the integrity of sensitive data across the entire security process.
- Optimizing Storage and Query Costs: By handling transformations such as parsing, normalization, and enrichment in our data pipelines, the need to store raw, unprocessed logs is eliminated. Our data pipelines compress data or index only essential fields, reducing storage overhead while retaining searchable fields. That maintains log coverage while minimizing costs associated with ingestion, storage, and querying.
- Real-Time Anomaly Detection: Our data pipelines can detect anomalies upstream by analyzing logs via sentiment analysis before they reach Splunk ES. You only need to forward events that deviate from normal behavior such as spikes in failed logins, and data exfiltration attempts. You can flag logs as "normal" and exclude them, while only suspicious or anomalous logs are ingested. That lowers the ingestion of routine logs but increases focus on logs relevant to security monitoring.
Practical Scenario
Imagine a scenario where the Observo AI data pipeline processes network logs, endpoint logs, and application logs:
- Filtering: Discards routine heartbeat messages and firewall drop logs.
- Aggregation: Aggregates frequent events like repeated failed logins into a single entry with a count.
- Enrichment: Appends threat intelligence tags such as "IP is linked to a known malware server" to logs with suspicious activity.
- Routing: Routes critical logs to Splunk ES and non-critical logs to AWS S3 for compliance purposes.
- Anomaly Detection: Identifies unusual traffic spikes with sentiment analysis and forwards those logs for ingestion while ignoring benign traffic.

Key Benefits
- Reduced Log Volume: By filtering, summarizing, and routing, our data pipelines decrease the number of logs ingested into Splunk ES.
- Improved Coverage: Comprehensive visibility is maintained by intelligently selecting logs from critical sources or summarizing trends from less critical ones.
- Lower Costs: Reducing ingestion volume saves on Splunk licensing and storage costs while retaining actionable insights.
- Optimized Performance: Splunk ES operates more efficiently by focusing on enriched, high-priority logs rather than processing vast quantities of raw data.
By leveraging these techniques, Observo AI data pipelines ensure that SOC teams have full visibility into their environment while optimizing costs and performance.
Wrapping Up
Observo AI is an official Splunk partner. To read more about how we make Splunk better, check out our blog about the partnership, “Unleashing the Power of Data: Announcing the Official Partnership Between Observo AI and Splunk.” If you want to get your hands on Observo AI to see the techniques described in this article for yourself, you can try it for free in our new Sandbox.